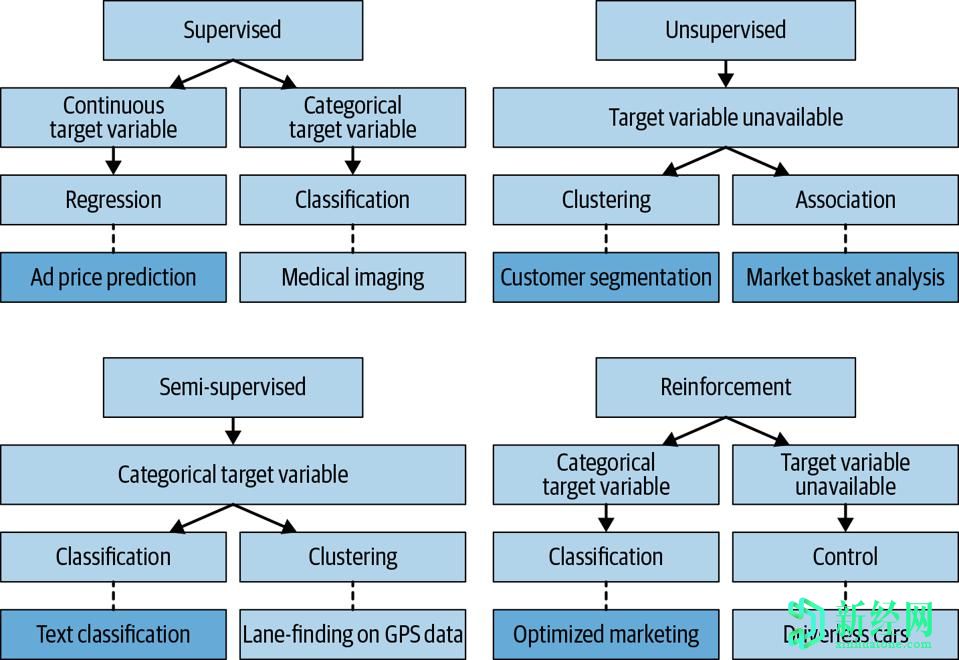
这是我基于Lomit Patel的“精益AI”(O'Reilly,ISBN:978-1-492-05931-8)的系列文章的第二部分。首先讨论的业务应用程序可以从监督学习中受益。本文将讨论无监督学习。同样,请参阅下面包含的本书的图5-1,以概述在机器学习(ML)中利用的四种主要人工智能(AI)类型。
大多数经理,包括生产线甚至是IT经理,都不需要了解机器学习的复杂性。但是,高水平的知识将帮助他们的组织理解AI是一种工具,并且必须与实际的业务问题联系起来。了解ML的高级分类如何与现实世界相关联,可以帮助技术人员和业务人员集中精力提供有效的解决方案。

快速提醒一下,有监督的学习是我们了解要确定的结果。然后可以选择我们需要的功能(参数,变量等等),并适当标记数据。这样一来,分析就可以检查数据,以了解它们在已知结果模式中的适合位置。
这并不总是可能的,也不是可取的。有时会有新的关系,这是意料之外的事情。在许多商业领域,尤其是在消费市场,要在竞争对手认识到相同的关系之前找出大量的数据来确定链接,从而提供至关重要的竞争优势。“无监督学习非常适合探索几乎不了解数据代表什么的数据。当您可能不确切知道要查找的内容时,这对于在原始数据中查找模式很有帮助。” Lomit Patel说。
让我们看几个例子。
客户细分
客户细分是核心的营销工具。目的是了解不同类型的买家,了解根据特征将个人群体联系起来的内容,然后建立可准确满足每个群体或客户群需求的营销活动。
乍一看,这似乎可以使用监督学习。毕竟,我们知道根据性别,年龄,收入以及我们可以定义的其他细分,并且可以将客户分类的特征。这种细分显然很适合监督学习,我们不应该忽略我们拥有的任何工具。
变化的是,我们拥有的有关个人,团体甚至公司的数据呈指数级增长。因此,例如,最终可能会导致在商店A购物的人们无论年龄如何都更有可能购买商品X。分析继续寻找基于数据对人员进行聚类的新方法,这些方法是我们从未想过的,而分类却无法进行。
这就是分类和聚类之间的区别,它们在较高的层次上听起来是一样的。监督学习是针对我们知道分类(癌症与无癌)的情况,而无监督学习则可以基于可能没有先前链接的变量对数据点进行聚类。借助无人监督的学习,客户细分正在变得更加先进。
协会
电子商务中每天都使用这一代码。每个人都看过购物,电影和其他网站,这些网站都在暗示“喜欢X的人也喜欢Z”。那就是联想。有监督的学习是行不通的,因为在表达出喜欢之前,我们不知道人们喜欢什么。通过构建可以分析那些喜欢的神经网络,无监督的训练可以导致系统从数据中学习以提出建议。这比基于当前的偏好来训练机器要好得多,因为正如每个营销人员都知道的那样,偏好并不是恒定不变的。
最后一句话很关键。癌症就是癌症。我们可能会发现新的癌症,或者找到一种新的检测现有癌症的方法。到那时,可以更新算法,但是我们仍在使用固定功能集确切指定机器应识别的内容。
关联,产品之间的关系,喜好等等通常是文化的一部分,并且该文化正在不断发生变化。一个强大的ML系统受过训练,可以查看所有数据并注意到以前未知的关系,甚至可以放松以前强大的关系。无监督学习使系统不受我们已经认为的了解的限制。
无监督学习:当您不知道会得到什么时
当您知道需要获得的结果时,有条理的学习是必经之路。但是,借助现代数据量,组织可以从看似无关的数据点获得新的出乎意料的见解。无监督学习是一种工具,可以帮助您找到那些可以在许多业务领域中获得洞察力的新关系,新模式和链接。
您可能已经注意到,世界上并非所有事物都是黑白的。好吧,有监督和无监督的学习并不是完全独立的。尽管上面的某些讨论暗示了这一点,但是本管理AI系列的下一篇文章将仅讨论–为什么混合系统有用。