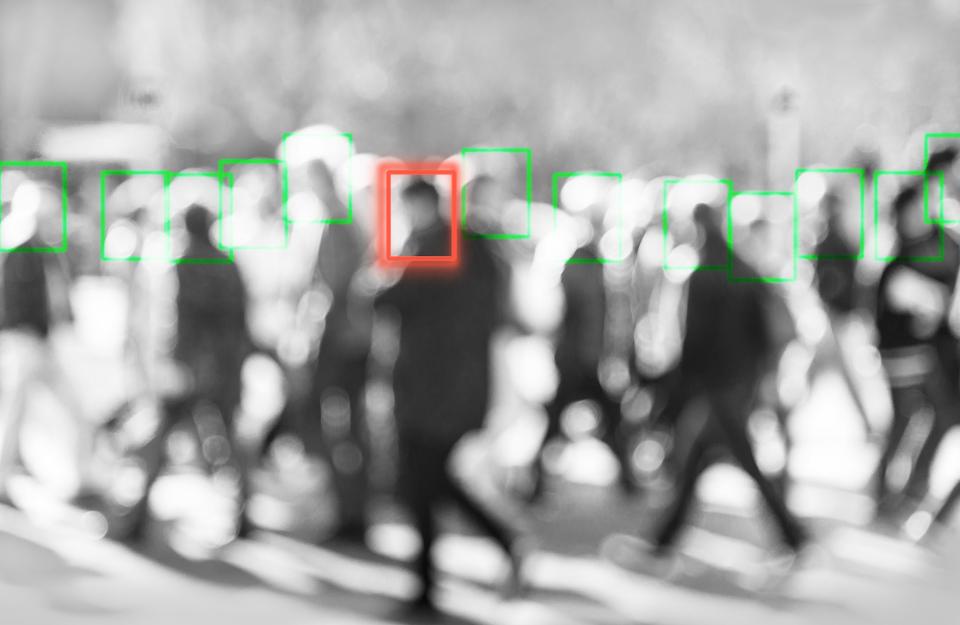人,自行车,汽车或道路,天空,草地:图像的哪些像素代表无人驾驶汽车前的不同前景人物或物体,哪些像素代表背景类别?这项称为全景分割的任务是一个基本问题,已在许多领域中应用,例如自动驾驶汽车,机器人技术,增强现实,甚至在生物医学图像分析中。在弗莱堡大学计算机科学系,Abhinav Valada博士是机器人学习的助理教授,也是BrainLinks-BrainTools的成员,他专注于这个研究问题。Valada和他的团队开发了最先进的“ EfficientPS”人工智能(AI)模型,该模型可以更快,更有效地对视觉场景进行连贯识别。

这项任务通常使用称为深度学习的机器学习技术来解决,其中人工神经网络弗赖堡研究人员解释说,它们是从人脑中汲取灵感,从大量数据中学习。诸如Cityscapes之类的公共基准在衡量这些技术的进步方面起着重要作用。Valada团队的成员Rohit Mohan说:“多年来,来自Google或Uber的研究团队一直在这些基准测试中争夺榜首。” 来自弗莱堡(Freiburg)的计算机科学家的方法已被开发出来,用于理解城市的城市场景,在“城市景观”(Cityscapes)中排名第一,Cityscapes是最有影响力的自动驾驶场景理解研究的排行榜。EfficientPS还始终在其他标准基准数据集(例如KITTI,Mapillary Vistas和IDD)上设置新的最新技术。
在项目网站上,Valada展示了团队如何在各种数据集上训练不同AI模型的示例。结果叠加在相应的输入图像上,其中颜色显示模型将像素分配给的对象类别。例如,汽车标记为蓝色,人物标记为红色,树木标记为绿色,建筑物标记为灰色。此外,AI模型还在每个被视为独立实体的对象周围绘制边框。弗莱堡大学的研究人员成功地训练了该模型,以将所学的城市场景信息从斯图加特转移到纽约市。尽管AI模型不知道美国的城市长什么样,但它能够准确识别纽约市的场景。
Valada解释说,以前解决该问题的大多数方法都具有较大的模型尺寸,并且在实际应用中(例如受资源严重限制的机器人技术)在计算上非常昂贵,“我们的EfficientPS不仅可以实现最新的性能,而且这也是计算效率最高,最快的方法。这进一步扩展了可以使用EfficientPS的应用程序。”