随着越来越多的人工智能应用程序转移到智能手机上,深度学习模型越来越小,以允许应用程序更快地运行并节省电池电量。现在,麻省理工学院的研究人员有了一种新的更好的压缩模型的方法。
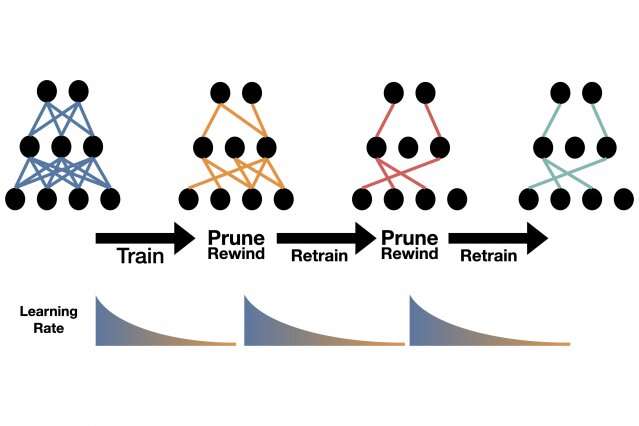
它是如此简单,以至于他们在上个月的一条推文中公开了它:训练模型,修剪其最弱的连接,以快速的早期训练速率对其进行重新训练,然后重复进行,直到模型达到您想要的尺寸为止。
“就是这样,”博士Alex Renda说。麻省理工学院的学生。人们修剪模型的标准操作非常复杂。”
Renda在本月远程召开的国际学习代表大会(ICLR)上讨论了该技术。伦达(Renda)是与博士生乔纳森·弗兰克(Jonathan Frankle)共同撰写的作品 麻省理工学院电气工程和计算机科学系(EECS)的学生,以及电气工程和计算机科学的助理教授迈克尔·卡宾(Michael Carbin)-计算机科学和人工科学实验室的所有成员。
去年,在ICLR上,富兰克尔和卡宾(Frankle and Carbin)获奖的彩票假说论文寻求更好的压缩技术。他们表明,如果在训练的早期发现正确的子网,则深度神经网络仅能执行十分之一的连接数。随着对训练更大的深度学习模型的计算能力和能量需求呈指数级增长,这一启示一直持续到今天。这种增长的代价包括,由于不属于大型科技公司的研究人员争夺稀缺的计算资源,导致全球变暖的碳排放量增加以及创新潜力下降。每天的用户也会受到影响。大型AI模型会消耗手机带宽和电池电量。
彩票假说引发了一系列主要是理论上的后续论文。但是在同事的建议下,弗兰克勒决定看看它可能会修剪什么课程,其中搜索算法会修剪搜索树中评估的节点数。这个领域已经存在了几十年,但是在神经网络在ImageNet竞赛中对图像进行分类的突破性成功之后,这个领域又重新出现了。随着模型的变大,研究人员增加了人工神经元的层以提高性能,其他人则提出了降低它们的技术。
现在担任麻省理工学院助理教授的宋瀚是一位先驱。在一系列有影响力的论文的基础上,Han提出了一种修剪算法,他称其为AMC或用于模型压缩的AutoML,这仍然是行业标准。在Han的技术下,多余的神经元和连接被自动删除,并对模型进行重新训练以恢复其初始精度。
作为对Han的工作的回应,Frankle最近在未发表的论文中建议,可以通过将较小的修剪后的模型倒回其初始参数或权重,并以更快的初始速率对较小的模型进行重新训练来进一步改善结果。
在当前的ICLR研究中,研究人员意识到该模型可以简单地倒退到其早期训练速度,而无需摆弄任何参数。在任何修剪方案中,模型变得越小,精度就越低。但是,当研究人员将此新方法与Han的AMC或Frankle的重绕方法进行比较时,无论模型缩小多少,其效果都更好。
目前尚不清楚修剪技术为何能如此出色地工作。研究人员说,他们将把这个问题留给其他人回答。研究人员说,对于那些想尝试的人,该算法与其他修剪方法一样容易实现,而无需花费时间进行调整。
“这是'Book'中的修剪算法,” Frankle说。“这很明显,通用并且很简单。”
就Han而言,现在从一开始就将重点从压缩AI模型转移到了引导AI上,以设计小型,高效的模型。他最新的方法“为所有人而做”也在ICLR上首次亮相。关于新的学习率方法,他说:“我很高兴看到新的修剪和再培训技术不断发展,使更多的人能够使用高性能的AI应用程序。”