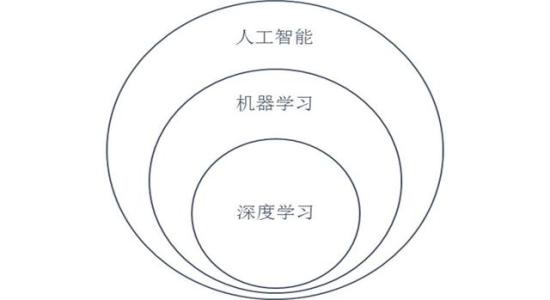
深度学习是机器学习的一个子领域,(一般来说)是受人类大脑及其功能启发的技术。在20世纪50年代首次引入,机器学习通过所谓的人工神经网络累积起来,人工神经网络是大量相互连接的数据节点,它们共同构成了人工智能的基础。

机器学习本质上允许计算机程序在外部数据或编程提示时自行改变。从本质上讲,它能够在没有人为干预的情况下实现这一点。它与数据挖掘具有相似的功能,但挖掘的结果由机器而不是人类处理。它分为两大类:有监督和无监督的学习。
监督机器学习涉及通过标记的训练数据推断预定操作。换句话说,监督结果事先由(人类)程序员知道,但推断结果的系统被训练为“学习”它们。相比之下,无监督机器学习从未标记的输入数据中得出推论,通常作为检测未知模式的手段。
与机器学习的线性算法相反,深度学习在通过分层算法训练自身的能力方面是独一无二的。深度学习层次结构越来越复杂和抽象,因为它们发展(或“学习”)并且不依赖于监督逻辑。简而言之,深度学习是一种非常先进,准确和自动化的机器学习形式,并且处于人工智能技术的最前沿。
深度学习的商业应用
机器学习已经在几个不同的行业中普遍使用。例如,社交媒体使用它来策划用户时间线中的内容供稿。Google Brain成立于几年前,旨在随着技术的发展,在Google的各种服务中实现产品化深度学习。
由于其专注于预测分析,营销领域特别投资于深度学习创新。由于数据积累是推动技术发展的动力,因此销售和客户支持等行业(已经拥有丰富多样的客户数据)具有独特的优势,可以在地面采用。
早期适应深度学习很可能是特定部门从技术中获益的关键决定因素,特别是在其最早阶段。然而,一些具体的痛点使许多企业无法投入深度学习技术投资。
大数据和深度学习的V
2001年,META集团(现为Gartner)的分析师Doug Laney概述了研究人员认为大数据的三大挑战:数量,种类和速度。十多年后,互联网接入点的快速增长(主要是由于移动设备的激增和物联网技术的兴起)使这些问题成为主要科技公司和小型企业的首要问题。和初创公司一样。
最近有关全球数据使用情况的统计数字令人震惊。研究表明,世界上大约90%的数据仅在过去几年内创建。根据一项估计,2016年全球移动流量约为每月7 艾字节,预计这一数字将在未来五年内增加约7倍。
超越数量,多样化(随着新媒体的发展和扩展,数据类型的快速增长)和速度(电子媒体发送到数据中心和集线器的速度)也是企业如何适应新兴领域的主要因素深度学习。为了扩展助记设备,近年来在大数据痛点列表中添加了其他几个v-words,包括:
有效性:大数据系统中输入数据准确度的测量。未检测到的无效数据可能会导致严重的问题以及机器学习环境中的连锁反应。
漏洞:大数据自然会引起安全问题,仅仅是因为它的规模。虽然通过机器学习在安全系统中看到了很大的潜力,但是他们当前化身的那些系统因其缺乏效率而受到关注,特别是由于它们倾向于产生错误警报。
价值:由于各种原因,证明大数据(在商业或其他地方)的潜在价值可能是一项重大挑战。如果此列表中的任何其他痛点无法有效解决,那么它们实际上可能会给任何系统或组织带来负面价值,甚至可能带来灾难性后果。
列表中添加的其他痛点包括可变性,准确性,波动性和可视化 - 所有这些都为大数据系统带来了独特的挑战。随着现有列表(可能)逐渐减少,可能仍会添加更多内容。虽然对某些人来说似乎有点做作,但助记符“v”列表包含了大数据所面临的严重问题,这些问题在深度学习的未来中发挥着重要作用。
黑匣子困境
深度学习和人工智能最具吸引力的特征之一是两者都旨在解决人类无法解决的问题。然而,应该允许的相同现象也呈现出一种有趣的困境,其形式为所谓的“黑匣子”。
通过深度学习过程创建的神经网络是如此庞大和复杂,其复杂的功能基本上是人类观察的不可理解的。数据科学家和工程师可能对深入学习系统的内容有了透彻的了解,但是他们如何更频繁地得出他们的输出决策是完全无法解释的。
虽然这可能不是营销人员或销售人员的重要问题(取决于他们的营销或销售),但其他行业需要一定数量的流程验证和推理才能从结果中获得任何用途。例如,金融服务公司可能会使用深度学习来建立高效的信用评分机制。但是,信用评分通常必须带有某种口头或书面解释,如果实际的信用评分方程完全不透明且无法解释,则难以形成。
这个问题也扩展到许多其他领域,特别是在健康和安全领域。医学和交通运输本身可以从深度学习中获益,但也面临着黑匣子形式的重大障碍。任何输出导致这些字段,无论多么有益,都可以完全丢弃,因为它们的底层算法是完全默默无闻的。这给我们带来了他们所有人中最具争议的痛点......
规
2016年春季,欧盟通过了“ 通用数据保护条例”(GDPR),该条例(除其他事项外)授予公民对机器学习系统产生的“显着影响”自动决策的“解释权”。该法规计划于2018年生效,引起了对由于其难以穿透的黑匣子而投资于深度学习的科技公司的担忧,这在很多情况下会妨碍GDPR规定的解释。
GDPR打算限制的“自动化个人决策”是深度学习的基本特征。但是,当歧视的可能性如此之高且透明度如此之低时,对这种技术的担忧是不可避免的(并且在很大程度上是有效的)在美国,食品和药物管理局同样通过要求这些过程保持可审计来规范药物的测试和营销。这给制药行业带来了障碍,据报道,总部位于马萨诸塞州的生物技术公司Biogen就是这种情况,由于FDA的规定,该公司已被禁止使用无法解释的深度学习方法。
深度学习(道德,实践和超越)的含义是前所未有的,坦率地说,是非常深刻的。对技术的大量担忧在很大程度上归功于其破坏性潜力与其不透明的逻辑和功能的结合。如果企业可以证明在深度学习中存在超过任何可能的威胁或危害的有形价值,那么它们可以帮助我们完成人工智能的下一个关键阶段。